The article is based on the following source:
We will focus on the LLaVA variant in this article.
Vision language models
The term vision language models here we are referring to the LLMs with vision capability. For LLaVA variant VLM, it consists of a pretrained vision module and a pretrained LLM and combined the two with the projector and module called multimodal projector and some fine-tuning. The following figure clearly demonstrates the relations between the components.
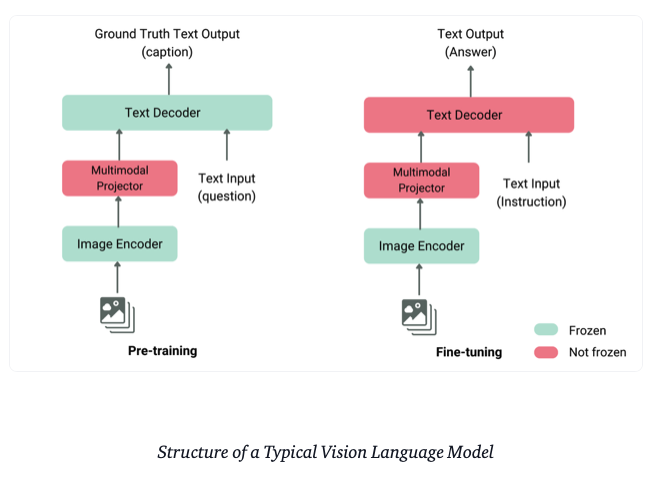
Training process in high level
LLaVA introduces a module multimodal projector to project the vision input to the embedding space of LLM tokens.
- Multimodal projector training. Use GPT-4 to generate questions whose answer is the caption. Use the QA set to train the multimodal projector while freezing other modules
- Instruction fine-tuning. Unfreeze the text decoder and fine tune the model with instruction and the corresponding answers
- The image encoder is frozen during the whole process
nanoVLM
Our Colab notebook here.
We use nanoVLM for understanding the details of training a VLM. We tweaked the Colab notebook shared by the author to make it runnable with the implementation code when we were studying it.
When we list the elements in a batch data, we see
- input_ids
- attention_mask
- images
- labels
input_ids
When we print the content of an input_ids sequence, we see the following structure
<im_end><im_end>...<im_start>user<row1_col1><image><image>...<row1_col2><image>...<image>Question...<im_end><im_start>assistant Answer: A<im_end><im_start>user...
- It would start with a sequence of
<im_end> - Following
<im_start>userand a sequence of image related tokens - After the image sequence token, it would have the question and following an
<im_end> - Next, start with
<im_start>assistantand following the corresponding answer and another<im_end> - The above is one back-and-forth between the user and the assistant. The following
<im_start>would kick off another back-and-forth between the user and the assistant
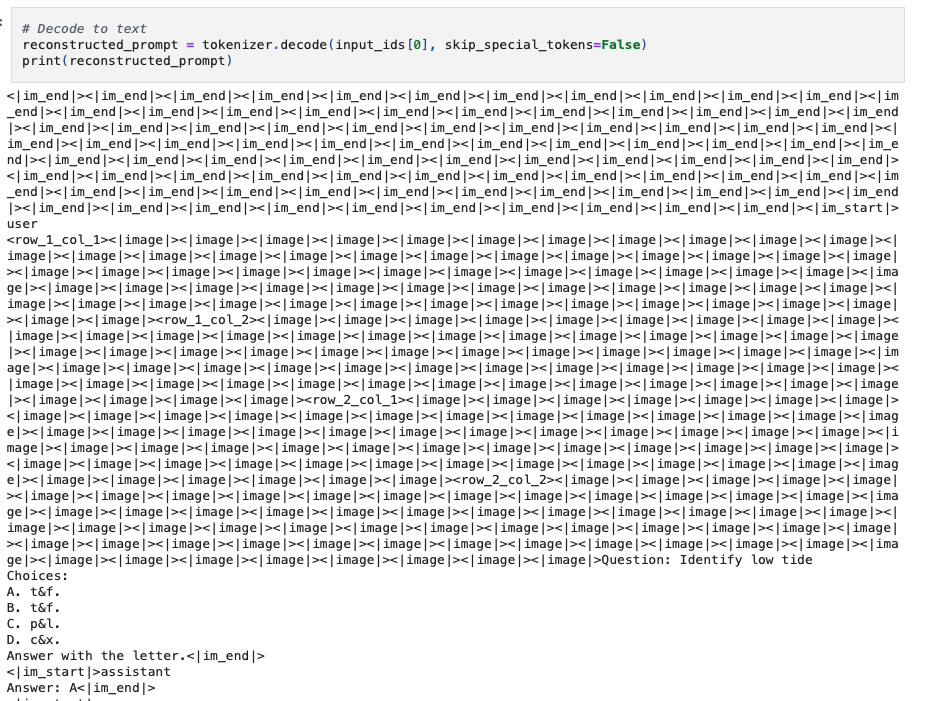
Why there are multiple <im_end> at the beginning?
<im_end>is the padding token in this notebook- We do the left side padding here
- However, if we do
print(tokenizer.padding_side)we would see the padding side isright - The reason is we don’t use the tokenizer to do the padding. In the codebase we do the padding ourselves here.
What are user and assistant?
- The LLM training here follows a user-agent-conversation-like chat template
- The dataset here is a VQA dataset and the questions would be treated as the users’ requests while the answers are the agent’s responses. [code reference1] [chat template]
- In this dataset, one image would have multiple questions. Therefore, we would see multiple turns of
<user>and<agnet>while only have one image at the beginning.
What is <row_1_col_1><image><image>...?
- From the config we see that an input image will be split into 16 regions max. For region, it would be segmented by the image encoder module into patches.
<row_1_col_1><image><image>...indicating it is the region on the row 1 and column 1 and the<image>following are the representation for patches generated by the image encoder. - In the notebook we visualize an example of one input image is split into 4 regions, as illustrated below

How does the images got processed?
- It’s possible that each training instances contains more than one image
- The
_process_imagesfunction would use the processor to convert each image into a list of regions. (It hasDynamicResizeandSplitImagecapability as here.) - The
get_image_stringfunction would obtain the correspondingimage_stringbased on the processed image
How does the model resolve multiple images in one training instances?
- We see there are three sequence of
<image>tokens distributed in the decoded input ids. It means that in this data instance, there are three sets of VQA and each one involved with one image and multiple questions The question is how does the model know which image to attend to when answering a question? - We don’t have answers at the moment.
labels
When we print the label tokens, we would see that only the assistant’s response will be used for loss computation. Other tokens would just be ignored.

attention_mask
When we print out the attention masks, we would see that only the padding token <im_end> would be ignored. If the <im_end> is not padding, it would not be ignored.

Image encoder
In this section we would introduce the image encoder used in LLaVA. From the LLaVA 1.5 paper it’s suggesting that it’s using the openai/clip-vit-large-patch14-336.
Regarding CLIP, the reference sources are
Key description from the paper
- We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet
The description above indicates that the CLIP embedding is the SOTA image representation at that time and the primary baselines it compared with in the paper is ImageNet.
Background
- Previously, the vision models are built based on labeled dataset
- VGG, ImageNet
- It requires specifying visual concept
- Directly learning the image representation from raw text is a promising alternative. It enables zero-shot transferable learning
Key results
- The embedding could perform zero-shot transferable tasks
- Match the accuracy of ResNet-50 on ImageNet without using their 1.28M training examples
Components
Natural language supervision
- Using natural language as training signal
- It’s much easier to scale on the natural language side compared to crowd-source-based for image labeling
- Connects representation to language and enable flexible zero-shot transfer
Large datasets
- Compose the datasets from the internet
- 400M pairs
- The dataset is named as WIT for WebImageText
- The details of constructing this dataset is missing. Here is the discussion thread and Meta’s effort to reproduce how to construct the dataset
- Blend YFCC100M dataset
Efficient pre-training
- Tried using CNN and text-transformer to generate the caption of a given image (Transformer language model)
- Generating exact caption is a very hard task
- It’s not working. On the other hand if we just predict BOW encoding we could speed up reaching the ImageNet performance by 3x
Projection (alignment)
- The paper tried both linear and non-linear projection
- No big difference
- Hypothesize here the language model signal is strong enough to guide the projection
- Hypothesize non-linear projection is good for image only self supervised representation
- Other alignment example
Model training
- InfoNCE loss. The loss is symmetric as computed with both image -> text and text -> image
- The batch size here is 32768