This article is based on the following content
- Paper Recommender Systems with Generative Retrieval (TIGER)
- Tech blog Training an LLM-RecSys Hybrid for Steerable Recs with Semantic IDs
Background
Current recommendation system is based on the two staged system. The first phase is candidate generation which has multiple channels covering different aspects of the system and each channel retrieves the candidate items for the next stage. The second phase is ranking phase. A large ranking model would rank the items from the first phase and decide the final ranking. This model would need to balance different objectives of the recommendation system and therefore it is very often that it is built in a multi-task learning setup.
For the first phase retrieval, it is usually done by embedding query search. That is, items are represented as embeddings. During the retrieval we would prepare the query embedding containing the relevant information and use nearest neighbor search to search for the top K items for the second phase.
Recently there is a trend that the retrieval is using autoregressive-style generate the identifiers for the retrieved items. The retrieval becomes decoding the semantic id tokens through a LM-like process instead of a nearest neighbor search.
Benefits:
- Semantic id decoding could have better cold-start and long-tail generalization
- The LM integration unlocks the power of user prompting and provide steerable RecSys experience
Semantic ID
The concept of semantic ID is proposed by Google’s TIGER paper. An overview could be illustrated with the below Figure from the paper.
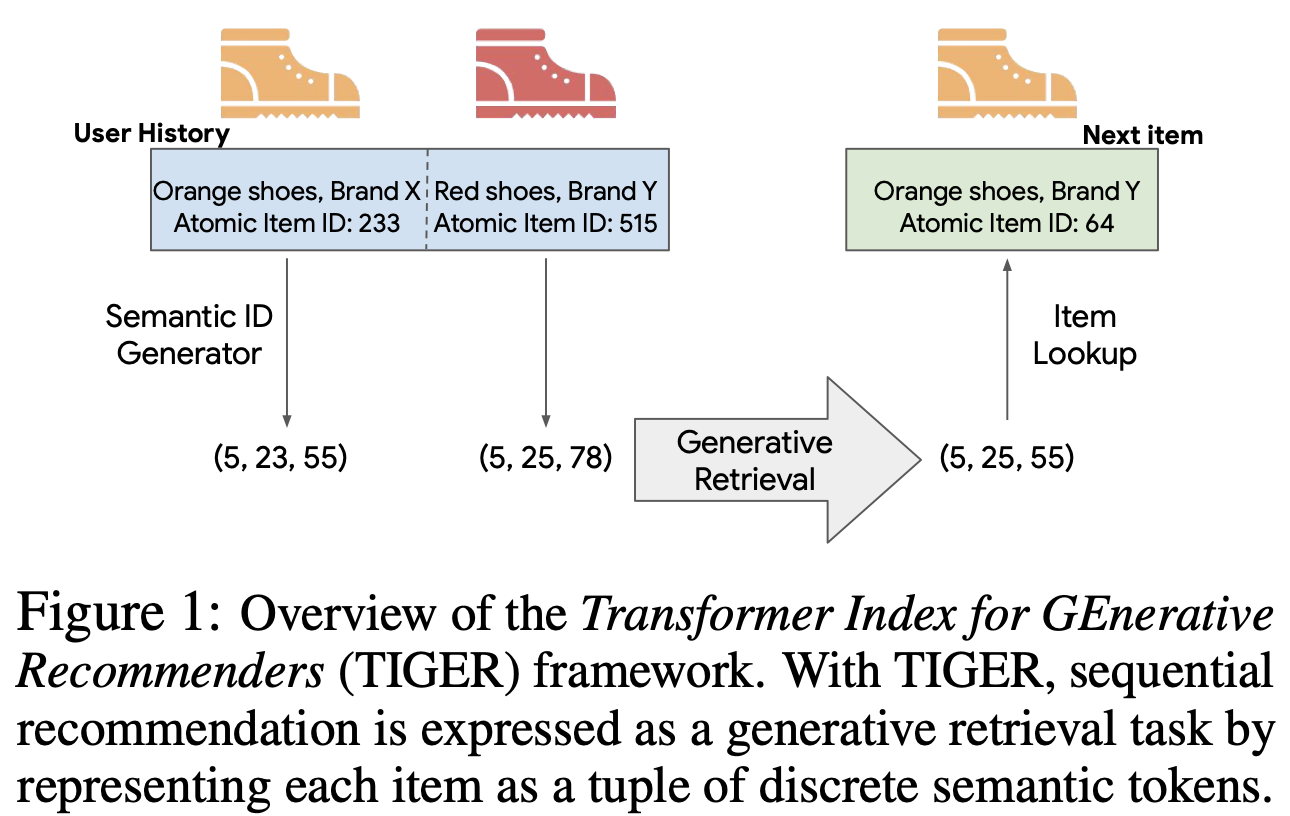
From the above figure we could see that each item is mapped to a code composed with three integers named semantic ids. These semantic ids they contain the relations between the items and therefore they could better be used in the LM-like training and application. In other wrods, the semantic ids are designed to have the following properties:
- Similarity: The similar items should have similar semantic ids
- Hierarchy. For an item with semantic id (10, 21, 35), item A (10, 23, 37) and item B (15, 21, 35), the item is more similar to item A since they have the same code on the first layer
RQ-VAE
My implementation
In the TIGER paper, the authors proposed using Residual-Quantized Variational AutoEncoder (RQ-VAE) to train the model.
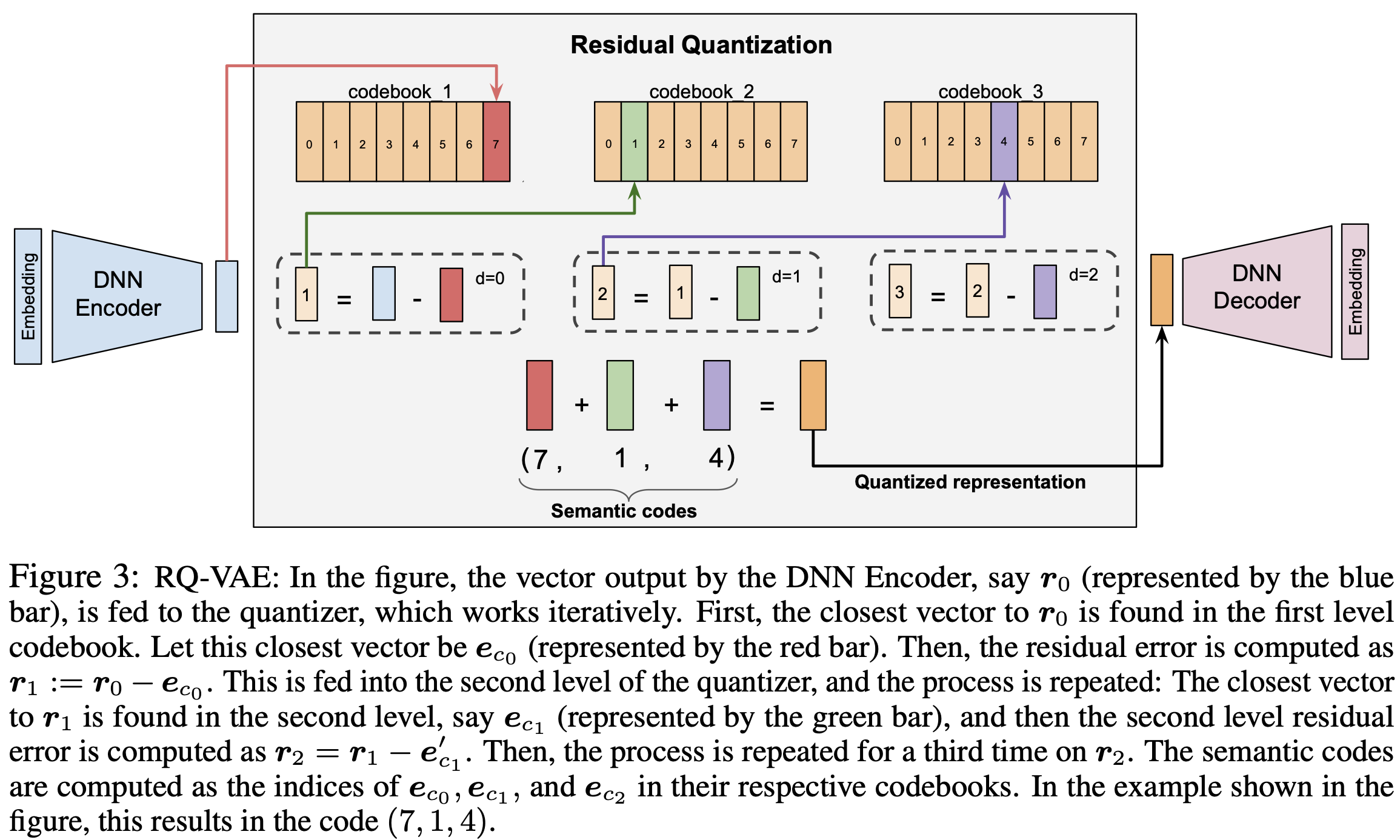
In our first attempt of implementation it is not successful, as we encountered the RQ-VAE collapse: the model assigned the same code to all inputs. How we measure if we successfully trained the model we called it code diversity. Ideally for each item/input we should assign a corresponding RQ-VAE code. Therefore, the overall code we assigned / overall item is our diversity metric. In our first attempt when the model collapsed, we have <0.1% diversity. Through several debugging and itereations, we finally reached 93.4% diversity as shown in the notebook above.
Straight through estimator
The key implementation of the forward pass is as below:
def forward(self, x):
x_n = self.normalize(x)
z = self.encoder(x_n)
if self.training:
z = self.pre_q_dropout(z)
q, codes, commit_loss, codebook_loss = self.codebook.forward_with_losses(z)
# CRITICAL: Straight-through estimator for gradient flow to encoder
# Forward pass: use quantized q
# Backward pass: treat quantization as identity, gradients flow to z
q_st = z + (q - z).detach()
x_hat = self.decoder(q_st)
recon = F.mse_loss(x_hat, x_n) # reconstruct normalized space (simplest)
loss = recon + self.cfg.alpha * codebook_loss + self.cfg.beta * commit_loss
return x_hat, loss, recon, codes
In the forward pass above, there is a critical piece of the implementation stratight-through estimator.
- If we don’t use the trick and directly go with
x_hat = self.decoder(q), the gradients would never flow into the encoder due to the operations inself.codebook.forward_with_losses(z) - When we are debugging by observing the reconstruction loss, we would still see it’s going down given the decoder would still overfit the reconstruction even the encoder’s output is random
- The best strategy for us to debug the situation like this is monitoring the gradients of each module
Layer level codebook loss
Another bug we had is regarding the codebook loss. In fact, for each level we would compute a codebook loss instead of only using the last layer. The codebook loss is implementaed below:
def forward_with_losses(self, residual: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""Quantize residual and compute per-level VQ losses for training.
Returns: (quantized, codes, commit_loss, codebook_loss) where
- quantized: [B, D] sum of per-level quantized vectors
- codes: [B, L] indices chosen per level
- commit_loss: sum of ||sg[r_l] - e_c_l||² over all levels
- codebook_loss: sum of ||r_l - sg[e_c_l]||² over all levels
"""
B, D = residual.shape
device = residual.device
codes = []
quantized_sum = torch.zeros_like(residual)
res = residual
commit_loss = 0.0
codebook_loss = 0.0
for l in range(self.levels):
emb = self.codebooks[l] # [K, D]
# find nearest neighbor
# dist(x, e)^2 = |x|^2 + |e|^2 - 2 x.e
x2 = (res**2).sum(dim=1, keepdim=True) # [B,1]
e2 = (emb**2).sum(dim=1) # [K]
scores = x2 + e2 - 2 * res @ emb.t() # [B,K]
idx = scores.argmin(dim=1)
codes.append(idx)
q = F.embedding(idx, emb)
# Per-level VQ losses as defined in the paper
commit_loss += F.mse_loss(res.detach(), q) # ||sg[r_l] - e_c_l||²
codebook_loss += F.mse_loss(res, q.detach()) # ||r_l - sg[e_c_l]||²
quantized_sum = quantized_sum + q
res = res - q
codes = torch.stack(codes, dim=1) # [B,L]
return quantized_sum, codes, commit_loss, codebook_loss
Dead code revival
The issue here is it’s possible that some codes are never used, meaning only assigned to a very limited number of items. We want to revive those dead codes. Procedure is as below
- We start with layer 0, we obtain the code assignment
- We check the assignment results and identify the dead codes with a usage threshold
- Assume we identify K dead codes, we replace the K centers for these code to revive them. We select the K residuals with highest norm as the new centers and add a small noise on them to add some randomness
- Finally, with the newly assigned dead codes we iterate over the next layer
Future direction
- Currently every level is using the same threhsold. However it makes more sense to have a threshold customized to each layer since the expected number of usage is different each level.
- How the new centers are decided are not convincing. We could have a better strategy for deciding them
@torch.no_grad()
def revive_dead_codes(model: RQVAE, data: torch.Tensor, min_usage: int = 5):
"""Revive dead or rarely-used codes by reinitializing them from high-variance data points."""
model.eval()
# Get all codes for the data
z = model.encoder(model.normalize(data))
# No LayerNorm - removed to prevent numerical explosion
# Compute residuals per level and track usage
res = z.clone()
for l in range(model.cfg.levels):
emb = model.codebook.codebooks[l]
# Find nearest codes
dist = torch.cdist(res, emb)
idx = dist.argmin(dim=1)
# Count usage
counts = torch.bincount(idx, minlength=model.cfg.codebook_size)
dead_codes = (counts < min_usage).nonzero(as_tuple=True)[0]
if len(dead_codes) > 0:
# Sample high-variance residuals to replace dead codes
# Use residuals with high L2 norm (far from current codebook)
residual_norms = (res ** 2).sum(dim=1)
_, high_var_idx = residual_norms.topk(min(len(dead_codes), len(res)))
# Reinitialize dead codes
n_revive = min(len(dead_codes), len(high_var_idx))
new_centers = res[high_var_idx[:n_revive]]
# Add small noise to avoid exact duplicates
new_centers = new_centers + 0.01 * torch.randn_like(new_centers)
model.codebook.codebooks[l][dead_codes[:n_revive]] = new_centers
print(f" [Revival] Level {l}: revived {n_revive} codes (had <{min_usage} uses)")
# Update residual for next level
q = F.embedding(idx, emb)
res = res - q
Data issue
During the early stage of debugging, we found that the inputs of our model are all the same. After some deep dive we found that we have data parsing issue.
- Amazon metadata ships as Python dict text ({‘key’: ‘value’}) but our data loaders expected JSON ({“key”: “value”}), yielding empty DataFrame
Fix: Patching the parsing function with ast.
def _parse_python_dict_lines(path: str):
"""Parse Python dict lines (not JSON) from a gzipped file using ast.literal_eval."""
import ast
import gzip
opener = gzip.open if path.endswith(".gz") else open
rows = []
with opener(path, "rt") as f:
for raw in f:
try:
line = raw.strip()
if line:
data = ast.literal_eval(line)
rows.append(data)
except (ValueError, SyntaxError, MemoryError):
continue
return rows
from tiger_semantic_id_amazon_beauty.src import data
data._parse_json_lines = _parse_python_dict_lines
Other strategies
We tried other strategies. Although they might help we don’t think they are the most critical ones. Other strategies/hypothesis we tried are as below
- LayerNorm on low-variance outputs causes numerical explosion: When encoder std ~0.005, LayerNorm amplifies by ~200x, creating 400k+ distances. Remove all normalization before quantization.
- Initialize codebook with encoded sample
# K-means init: encode samples before seeding codebooks
with torch.no_grad():
sample = data[torch.randperm(data.shape[0])[: min(batch_size, data.shape[0])]].to(device)
encoded_sample = model.encoder(sample)
model.codebook.kmeans_init(encoded_sample)
- Using Kaiming initialization