Paper: DeepRec: Towards a Deep Dive Into the Item Space with Large Language Model Based Recommendation
In this paper, we introduce an approach of how to leverage LLM for the sequential ranking task.
Background: LLM with RecSys
In general, we have three major ways of how LLMs could be used in the ranking combined with traditional recommendation model (TRM).
LLM-enhanced TRM
- LLMs can provide extra features about items or augment user interaction data for TRMs
TRM-enhanced LLM
- LLMs accept user interaction history \(X\) and retrieved items \(I\) from TRMs as the input to predict the next item \(y\)
LLM as RecSys
- Map all items into a concise item space (vocabulary)
- Make input items as tokens and predict the next item
In the paper, it proposes a new way which is leveraging LLM’s interaction with TRM for the exploration and make the final recommendation.
DeepRec
- Multi-turn
- Existing LLM-based RecSys are all limited to one-time recommendation, which are inherently shallow in their exploration of the item space. To address this, the idea is to extend the interaction between LLMs and TRMs to a multi-turn retrieval paradigm for wider exploration.
- User input sequence \(X\) -> LLM generate thoughts -> LLM generate user preference -> TRM retrieval -> {thoughts -> user preference -> TRM retrieval loop x m turns} -> Final ranking
Recommendation Model Based Data Rollout
- It is hard to have the label for the interaction between LLM and TRM
- The authors use RL to train the model. They run LLM to interact with the TRM collect the interactions and have rewards on the interaction
- For the interaction, when we hit <|end_of_preference|>, we would stop the generation (break out the for loop token inference) and ask TRM to generate candidates. And we would attach the candidates and continue the process
- TRM retrieval
- 0.5 * (TRM \(X\) embedding + text encoding) and use the embedding to dot product the item embedding
- (Comment) This is somewhat weird…given the text embedding and TRM embedding are not in the same embedding space
- TRM retrieval
- For the interaction, when we hit <|end_of_preference|>, we would stop the generation (break out the for loop token inference) and ask TRM to generate candidates. And we would attach the candidates and continue the process
- The final output format would looks like <think> (interaction going on) </thing> <recommendation_list> (the list)</recommendation_list>
- Each interaction trajectory in the format above would be a data instance and we would assign rewards to them for RL training
- Difficulty-based data selection: If the label item is outside the top 100 of the final ranking list, the data instance would be considered too difficult and be discarded
Rewards
- There are two levels of rewards introduced
- Process level
- More focusing on the format / process
- Format reward: Check if the output format is correct
- Invocation count reward: Encourage the model to have more interaction turns with TRM
- Preference diversity reward: Encourage the model to explore different user preference
- Using the text embedding to compute the similarity of the output user preference between different turns
- Outcome level
- More focusing on whether the recommendation is correct. Suppose the final recommendation list size is \(K\)
- Point wise reward: For every item in the predicted list, compute it’s title and TRM embedding similarity of the target item. The final reward is weighted average using the ranking of the item. The authors call it model-based point-wise rewards since the recommendation data is very sparse
- TRM embedding: For example, in SASRec it used the input sequence’s last item’s embedding to do the retrieval. Here the last item’s embedding
- List-wise reward: Check if the target item is in the final list
- Rank reward: The ranking of the target item in the final list
Two stage RL training
- Stage 1: Only focus on process level reward (For stability)
- Stage 2: Focus on rFormat + outcome level reward
- (Not include invocation and diversity here since we want to prevent the model gaming the reward by repeating the reasoning while not focusing on learning outcome)
Implementation
- LLM: Qwen2.5-7B-Base
- RL algorithm: Reinforce++ algorithm
- OpenRLHF framework
- There are potentially many iterations to train the model. In each iteration, we generate 128 * 8 = 1,024 samples and train the model with batch size 512 and 20 + 80 = 100 steps.
Note
- In the POC code with Colab, we found that if cat is not initially searched, it would be hard for training as the training goes longer. The model would converge to weird location. Therefore, exploration enough is important in RL training.
- To me, the reason why this multi-turn interaction would work would rely on the assumption that the LLM knows all the information about lots of movies. The retrieval is just helping the LLM to know whether the RecSys has the suitable movies on its mind which are based on the user’s interaction history
The below figure is the overview of DeepRec. 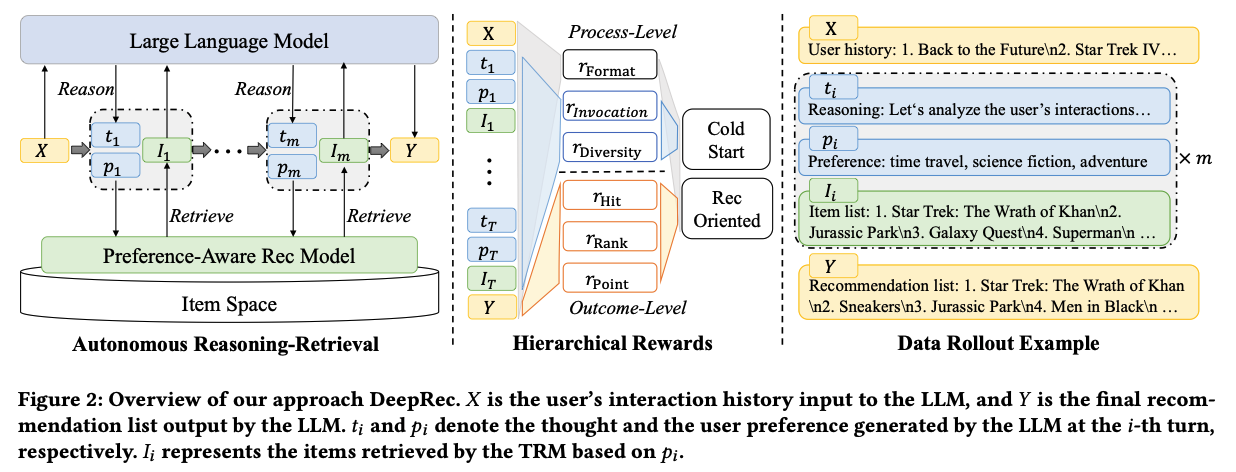
Implementation
- A toy example of training LLM with RL here